はじめに
このスクリプトは、複数の pandas.DataFrameを Excel ファイルに保存し、同時に pickle ファイルとしてもバックアップする処理をするものです。xlwings を使用し、Excel ファイルの書式を整えながらデータを保存します。
目次
df_to_excel.py
ソースコード
import pickle
from pathlib import Path
import xlwings as xw
def df_to_excel(dir_path, df1, df2, df3, df_list, df5):
"""複数の DataFrame を Excel ファイルに保存し、pickle にも保存する"""
dir_path = Path(dir_path)
file_path = dir_path / "Python_Sample.xlsx"
# `with` ステートメントで Excel プロセスを適切に管理
with xw.App(visible=False) as app:
wb = app.books.add()
# 各 DataFrame を指定のシートに書き込む
ws1 = wb.sheets.add("uriage", after=wb.sheets[-1])
ws1.range("A1").value = df1
ws2 = wb.sheets.add("kokyaku_daicho", after=wb.sheets[-1])
ws2.range("A1").value = df2
ws3 = wb.sheets.add("merged_data", after=wb.sheets[-1])
ws3.range("A1").value = df3
ws4 = wb.sheets.add("pivot_table", after=wb.sheets[-1])
# `pivot_table` のデータを書き込む
start_row = 1
for df in df_list:
ws4.range(f"A{start_row}").value = df
start_row += df.shape[0] + 2 # 1行空ける
ws5 = wb.sheets.add("unused_users", after=wb.sheets[-1])
ws5.range("A1").value = df5
# 既存の `Sheet1` を削除
if "Sheet1" in [s.name for s in wb.sheets]:
wb.sheets["Sheet1"].delete()
# 全シートの列幅を自動調整
for sheet in wb.sheets:
sheet.autofit("columns")
# 最初のシートをアクティブに
wb.sheets[0].activate()
# Excel ファイルを保存して閉じる
wb.save(file_path)
wb.close() # `wb` を明示的に閉じる
# Pickle ファイルの保存
save_pkl(dir_path, df1, df2, df3, df_list, df5)
print(f"Excelファイル '{file_path}' にデータを保存しました。")
def save_pkl(dir_path, df1, df2, df3, df_list, df5):
"""各 DataFrame を pickle ファイルとして保存"""
file_paths = {
"uriage.pkl": df1,
"kokyaku_daicho.pkl": df2,
"merged_data.pkl": df3,
"pivot_table.pkl": df_list,
"unused_users.pkl": df5,
}
for file_name, df in file_paths.items():
with open(dir_path / file_name, "wb") as f:
pickle.dump(df, f)
処理の概要
このスクリプトは以下の処理を行います。
- Excelファイルへの出力:
df_to_excel()で DataFrame を指定のシートに書き込み。 - Excelの書式設定: 列幅を自動調整し、最初のシートをアクティブ化。
- Pickleファイルの保存:
save_pkl()でデータを.pklファイルとして保存。
Excelファイルへの出力
df_to_excel() は、複数の DataFrame を Excel ファイルに書き出します。
def df_to_excel(dir_path, df1, df2, df3, df_list, df5):
"""複数の DataFrame を Excel ファイルに保存し、pickle にも保存する"""
dir_path = Path(dir_path)
file_path = dir_path / "Python_Sample.xlsx"
# `with` ステートメントで Excel プロセスを適切に管理
with xw.App(visible=False) as app:
wb = app.books.add()
# 各 DataFrame を指定のシートに書き込む
ws1 = wb.sheets.add("uriage", after=wb.sheets[-1])
ws1.range("A1").value = df1
ws2 = wb.sheets.add("kokyaku_daicho", after=wb.sheets[-1])
ws2.range("A1").value = df2
ws3 = wb.sheets.add("merged_data", after=wb.sheets[-1])
ws3.range("A1").value = df3
ws4 = wb.sheets.add("pivot_table", after=wb.sheets[-1])
# `pivot_table` のデータを書き込む
start_row = 1
for df in df_list:
ws4.range(f"A{start_row}").value = df
start_row += df.shape[0] + 2 # 1行空ける
ws5 = wb.sheets.add("unused_users", after=wb.sheets[-1])
ws5.range("A1").value = df5
# 既存の `Sheet1` を削除
if "Sheet1" in [s.name for s in wb.sheets]:
wb.sheets["Sheet1"].delete()
# 全シートの列幅を自動調整
for sheet in wb.sheets:
sheet.autofit("columns")
# 最初のシートをアクティブに
wb.sheets[0].activate()
# Excel ファイルを保存して閉じる
wb.save(file_path)
wb.close() # `wb` を明示的に閉じる
# Pickle ファイルの保存
save_pkl(dir_path, df1, df2, df3, df_list, df5)
print(f"Excelファイル '{file_path}' にデータを保存しました。")xlwingsを使用し、各 DataFrame を Excel の指定シートに書き込む。pivot_tableのデータをまとめて書き込み、間に空行を挿入。- 既存の
Sheet1を削除し、列幅を自動調整。
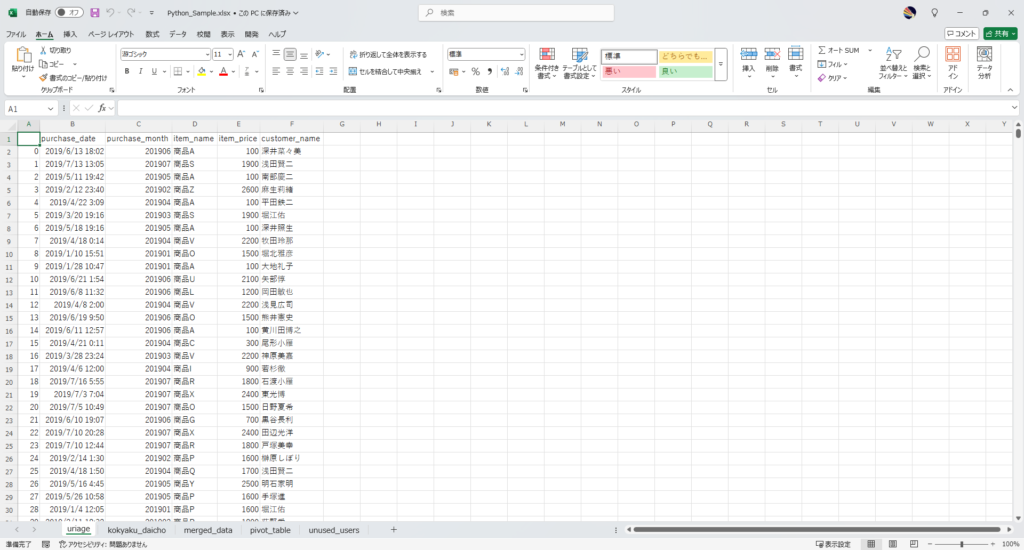
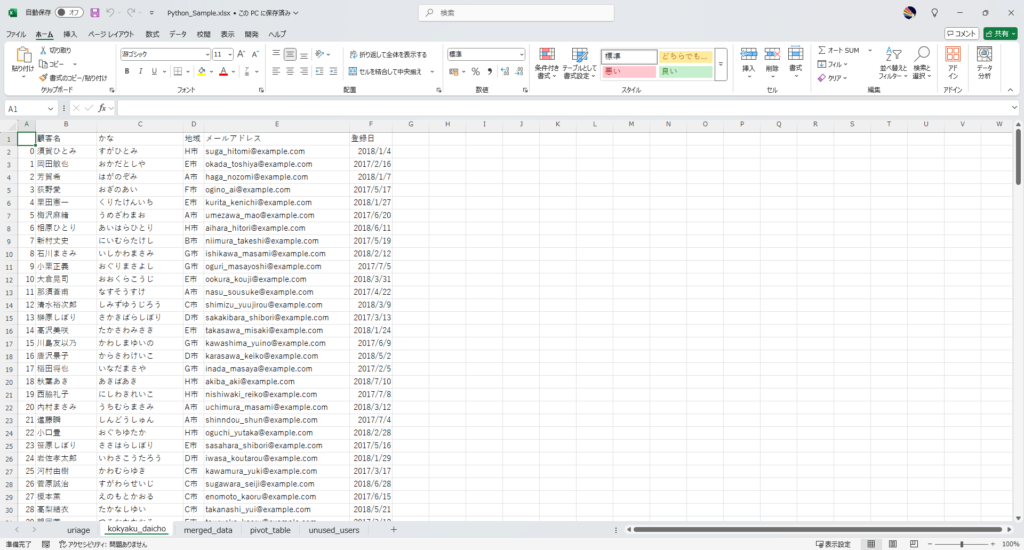
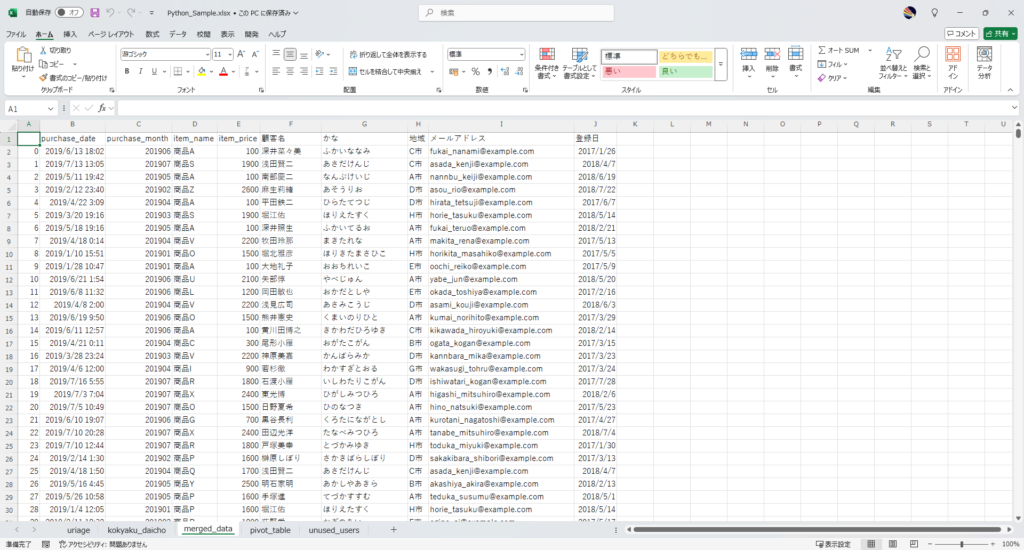
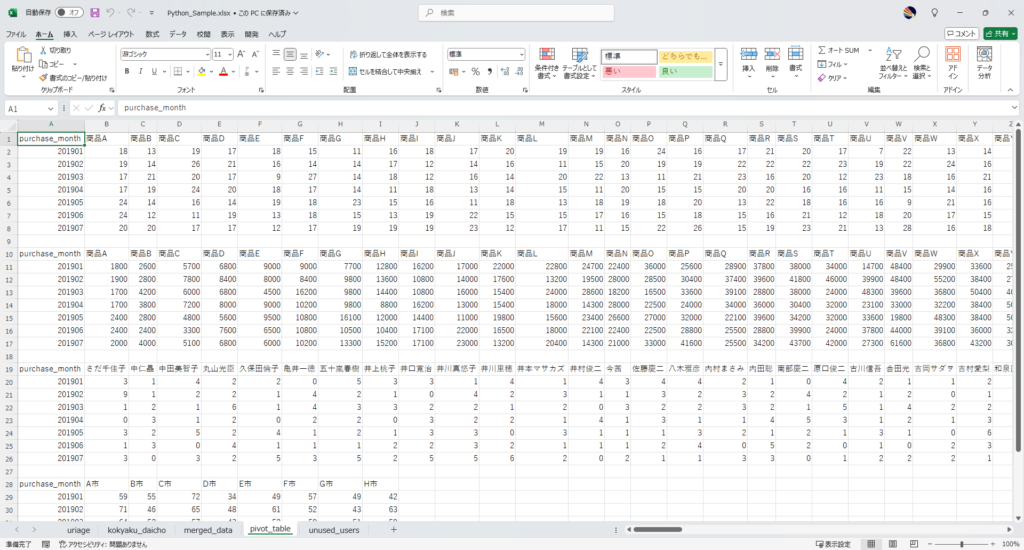
Pickleファイルの保存
save_pkl() は、Excel に出力したデータを .pkl ファイルとして保存します。
def save_pkl(dir_path, df1, df2, df3, df_list, df5):
"""各 DataFrame を pickle ファイルとして保存"""
file_paths = {
"uriage.pkl": df1,
"kokyaku_daicho.pkl": df2,
"merged_data.pkl": df3,
"pivot_table.pkl": df_list,
"unused_users.pkl": df5,
}
for file_name, df in file_paths.items():
with open(dir_path / file_name, "wb") as f:
pickle.dump(df, f)- 各 DataFrame を
.pkl形式で保存。 pickle.dump(df, f)によりバイナリ形式で保存し、再利用可能に。
このスクリプトを活用することで、Excel ファイルへの出力と同時にデータのバックアップを取ることができ、データ分析の効率を向上させることが可能 です。
コメント